В A-Parser 1.2.138добавлена эмуляция node версии 8.9.x с поддержкой загрузки модулей и частичной реализацией fs и net модулей. Это дает возможность обращаться из JavaScript парсеров напрямую к файловой системе, а также использовать подключение по TCP из модулей к другим сервисам(например mysql, redis, chrome...).
Все это позволило загружать и использовать node модули из каталога npm, в котором собраны множество полезных библиотек для обработки данных, коннекторы к базам данных и множество других интересных вещей. На данный момент протестированы следующие модули: md5, async-redis, jsdom, puppeter.
Улучшения
Добавлена поддержка Node.js модулей в JavaScript парсерах
Как известно, сейчас Google при парсинге очень часто выдает рекаптчу, что значительно усложняет и замедляет сбор данных.
В A-Parser есть возможность обходить данную проблему, разгадывая рекаптчу с помощью сторонних сервисов. Поддерживаются различные онлайн сервисы, а также программные решения.
Одним из таких решений есть XEvil. Его использование дает хороший прирост в скорости, а также значительно удешевляет парсинг, ведь здесь нету оплаты за количество разгаданных каптч/рекаптч, как в онлайн сервисах. Кроме этого, XEvil умеет разгадывать практически любые обычные каптчи (в виде картинки) и данная возможность также поддерживается в A-Parser.
На данный момент использовать разгадывание рекаптчи с помощью XEvil можно в таких парсерах:
Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
21-й сборник рецептов. В нем мы научимся отправлять сообщения в Telegram прямо из A-Parser, изучим работу с модулями Node.js в JS парсерах на примере решения задачи фильтрации по множеству признаков, а также спарсим весь IMDb. Поехали!
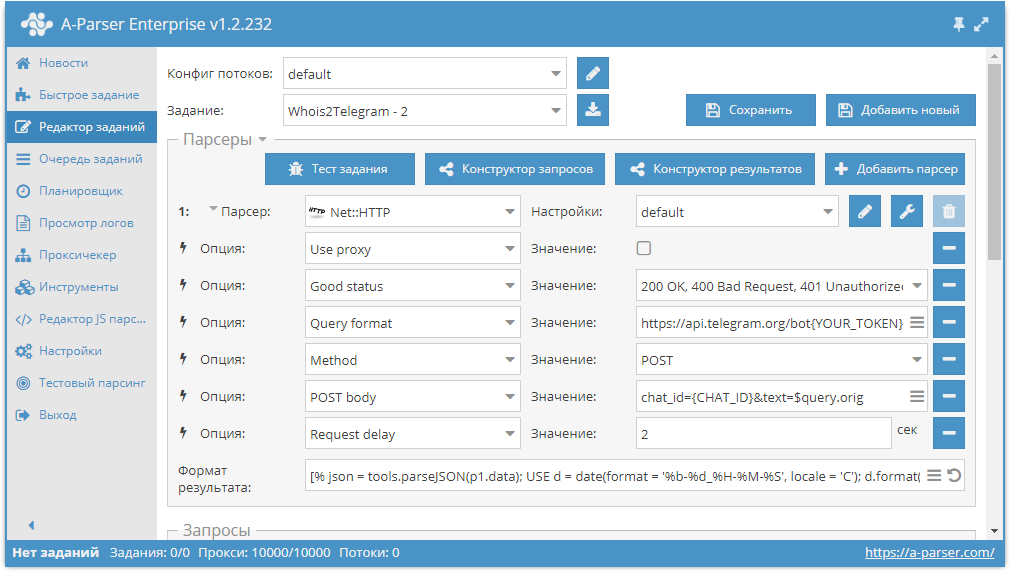
Telegram является одним из самых популярных мессенджеров благодаря своей простоте, и в то же время большому функционалу. Среди прочего, в Телеграме можно создавать ботов, с помощью которых можно делать чаты более интерактивными. Взаимодействие с ботом на на стороне сервера происходит через Telegram Bot API. Используя эти возможности, можно легко и буквально за несколько минут настроить уведомления себе в Telegram прямо из парсера. О том, как это сделать, а также несколько реальных примеров - по ссылке выше.
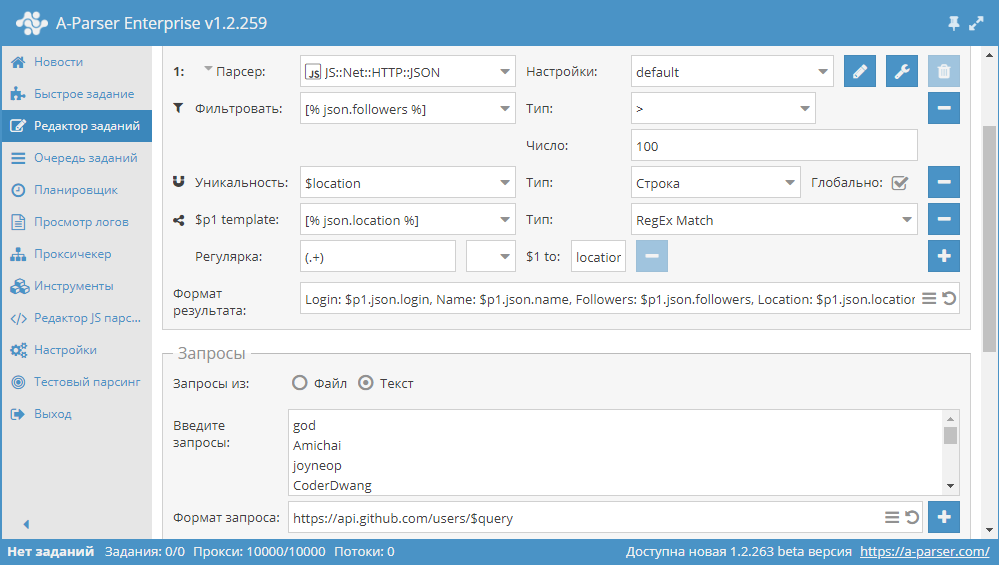
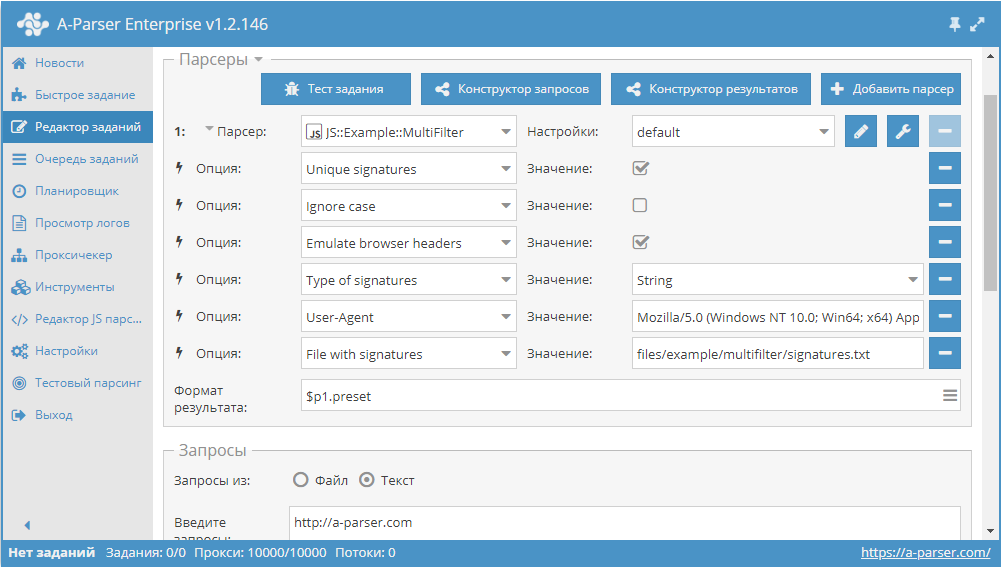
Как известно, для фильтрации в А-Парсере используется встроенный функционал фильтров. Но бывают ситуации, когда список признаков, наличие которых нужно проверять, очень большой и его сложно вписать в строку стандартного фильтра.
Начиная с версии 1.2.127 в A-Parser добавлена поддержка модулей Node.js. Благодаря этому появилась возможность читать список признаков из файла и использовать его для проверки страниц. О том, как это сделать, а также готовый парсер с мультифильтром - по ссылке выше.
Пример решения задачи по сбору данных о фильмах и их рекомендаций на IMDb. Данная статья показывает, как можно решать задачи, которые на первый взгляд требуют много времени и ресурсов, буквально за несколько часов. Узнать о том, как спарсить весь IMDb за 1,5 часа, а также посмотреть пресет и забрать готовую базу можно по ссылке выше.
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Исправлена работа с переменными при их создании в Parse custom results, а также при использовании нижнего подчеркивания в именах в Конструкторе результатов
Исправлена работа tools.js, баг появился в одной из предыдущих версий
Исправлен баг, из-за которого А-Парсер падал на некоторых ОС, появился в одной из предыдущих версий
Третье видео в цикле уроков по созданию JavaScript парсеров. Здесь рассказано о том, как написать JS парсер, в котором будет поддержка антигейта для разгадывания каптч на страницах.
В уроке рассмотрено:
Создание JS-парсера для разгадывания капчи
Работа с объектом this.captcha внутри JavaScript кода
Описание процесса разгадывания каптчи, реализованного в A-Parser
Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
22-й сборник рецептов. В нем мы разберемся, как проверять индексацию всех страниц сайта одновременно в нескольких поисковиках, научимся парсить данные по ссылкам из выдачи одним заданием и будем искать сабдомены на сайтах. Поехали!
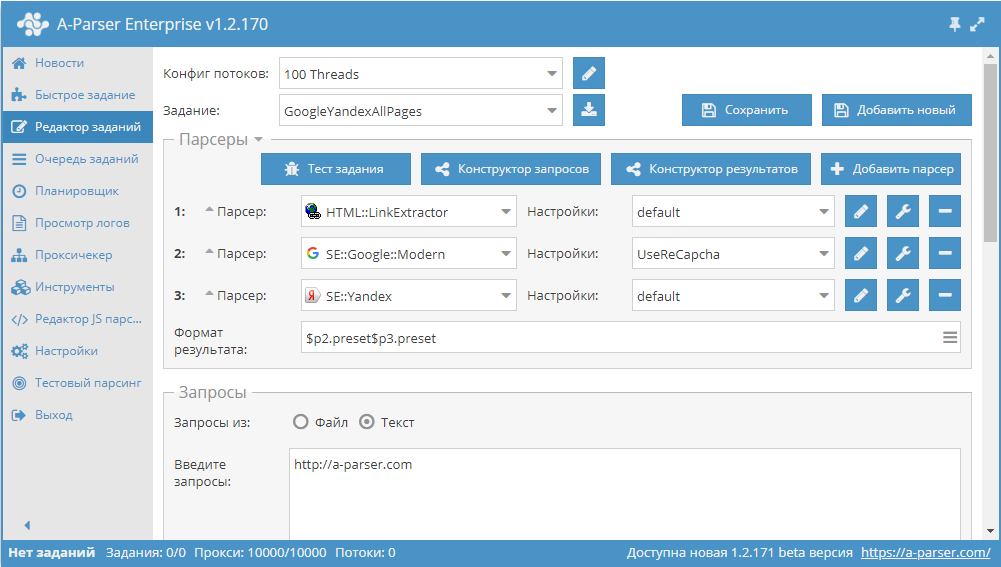
Данный пресет позволяет спарсить ссылки на все страницы сайта и одновременно проверить их на предмет индексации поисковиками (в примере Google и Яндекс, можно по аналогии добавить другие ПС). Готовый пресет и описание по ссылке выше.
Пример использования tools.query.add в JavaScript парсерах. Данный парсер получает ссылки из выдачи, после чего собирает из каждой страницы title и description. И все это одним заданием с максимальной производительностью, благодаря многопоточному парсингу. Парсер с описанием доступны по ссылке выше.
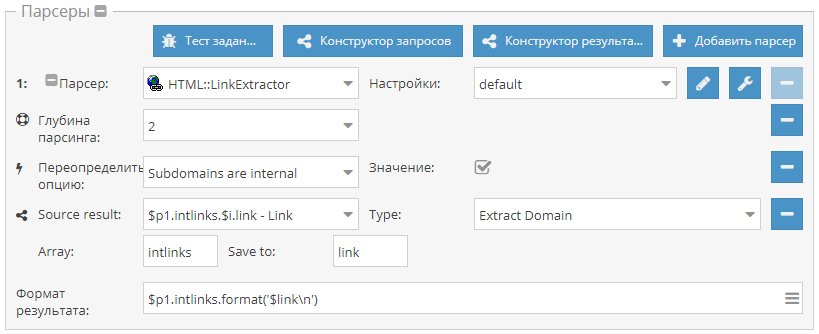
Небольшой пример, который демонстрирует, как собрать поддомены одного или нескольких сайтов. Используется
HTML::LinkExtractor и Parse to level для прохода вглубь по страницам сайта. При этом Конструктором результатов извлекаются из внутренних ссылок домены и выводятся с уникализацией по строке. Готовый пресет - по ссылке выше.
В этом сборнике статей мы рассмотрим все возможные варианты решения задачи прохода по пагинации на сайтах, очень детально изучим работу с переменными в JavaScript парсерах, а также попробуем работать с базами данных SQLite на примере парсера курсов валют. Поехали!
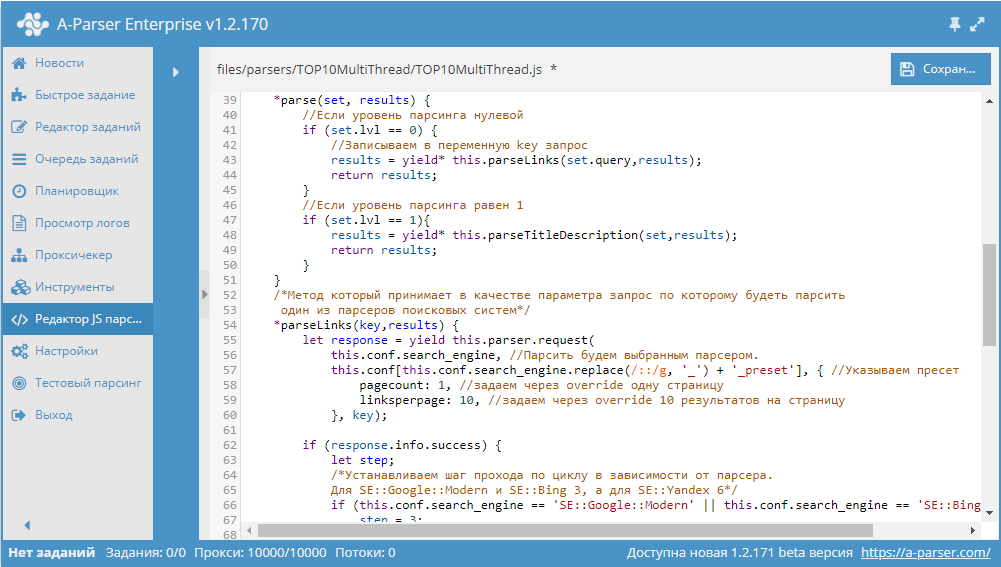
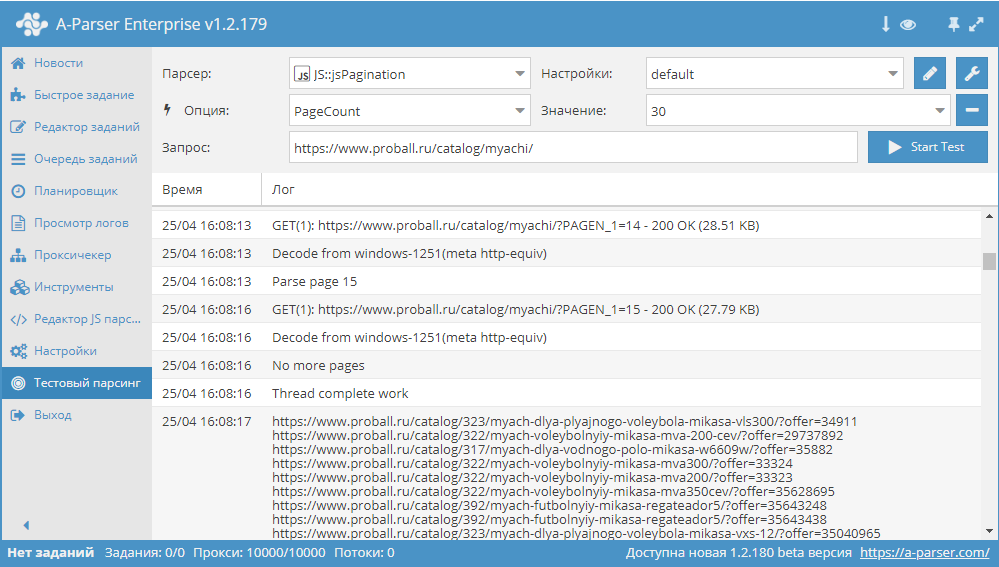
В A-Parser существует несколько способов, с помощью которых можно реализовать проход по пагинации. В связи с их разнообразием, становится актуальным вопрос выбора нужного алгоритма, который позволит максимально эффективно переходить по страницам в процессе парсинга. В этой статье мы постараемся разобраться с каждым из способов максимально подробно. Также будут показаны реальные примеры и даны рекомендации по оптимизации многостраничного парсинга. Статья - по ссылке выше.
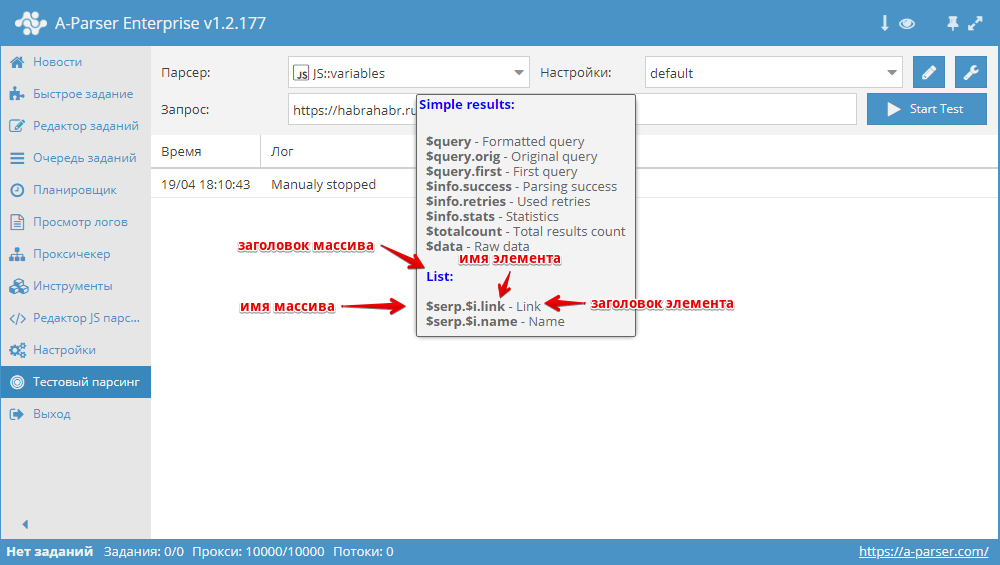
JS парсеры в А-Парсере появились уже около года назад. Благодаря им стало возможным решать очень сложные задачи по парсингу, реализовывая практически любую логику. В этой статье мы максимально подробно изучим работу с разными типами переменных, а также узнаем, как можно оптимизировать работу сложных парсеров. Все это - в статье по ссылке выше.
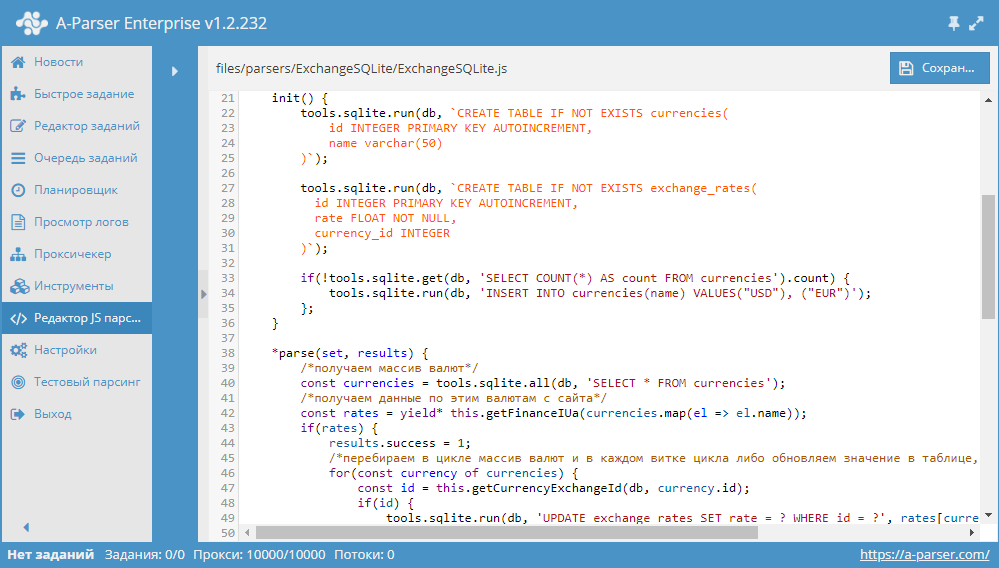
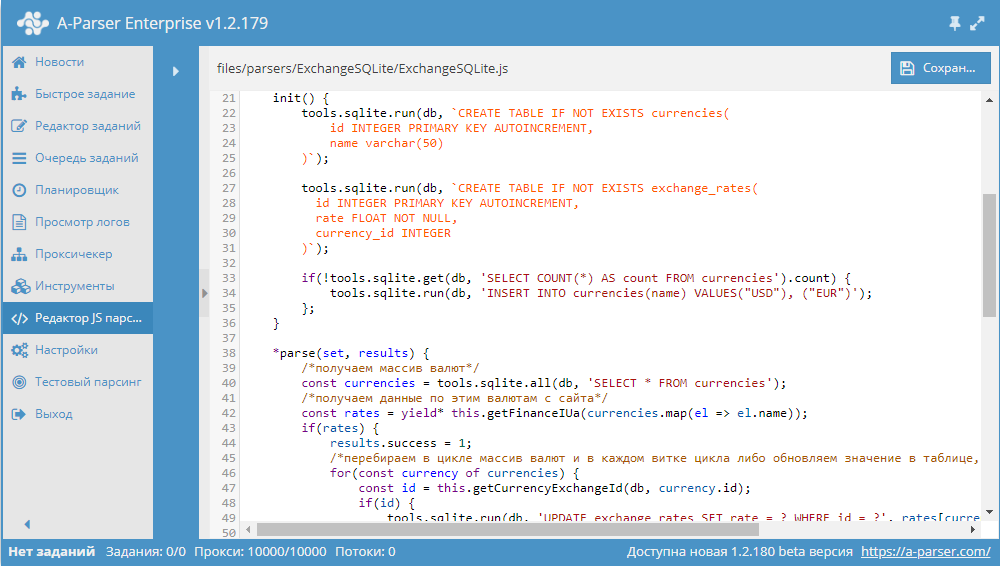
Начиная с версии 1.2.152 в A-Parser появилась возможность работать с БД SQLite.
В данной статье мы рассмотрим разработку JavaScript парсера, который будет парсить курсы валют из сайта finance.i.ua и сохранять их в БД. В результате получится парсер, в котором продемонстрированы основные операции с базами данных. Подробности, а также готовый парсер - по ссылке выше.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
23-й сборник рецептов. В нем мы будем парсить категории сайтов из Google, научимся формировать файлы YML, а также разберемся, как парсить даты и преобразовывать их в единый формат. Поехали!
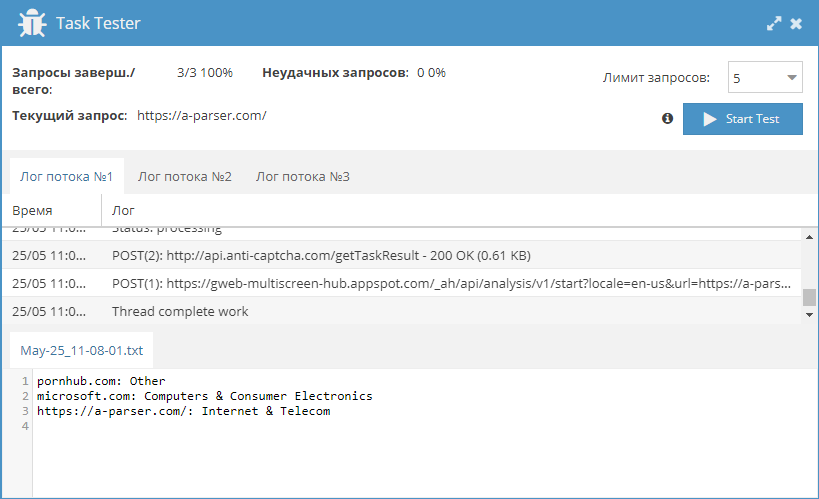
Категоризация сайтов - довольно актуальная задача, но существует немного сервисов, которые могут ее решить. Поэтому, по ссылке выше можно взять небольшой парсер, который позволяет получать категории сайтов из Google.
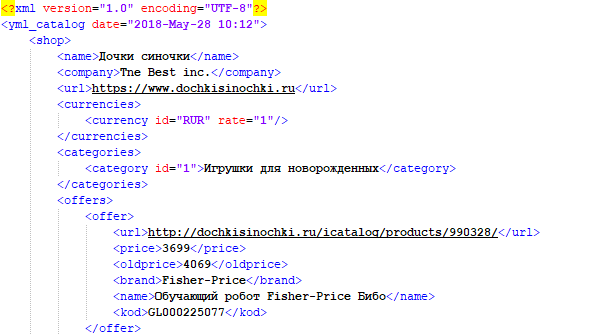
YML - это стандарт, разработанный Яндексом для работы с Маркетом. По своей сути, это файлы, схожие с XML, в которых содержится информация о товарах в интернет-магазине. Данный формат обеспечивает регулярное автоматическое обновление каталога на Яндекс.Маркет и позволяет отражать все актуальные изменения (наличие, цена, появление новых товаров). Пример парсинга интернет-магазина и сохранения собранных данных в YML можно посмотреть по ссылке выше.
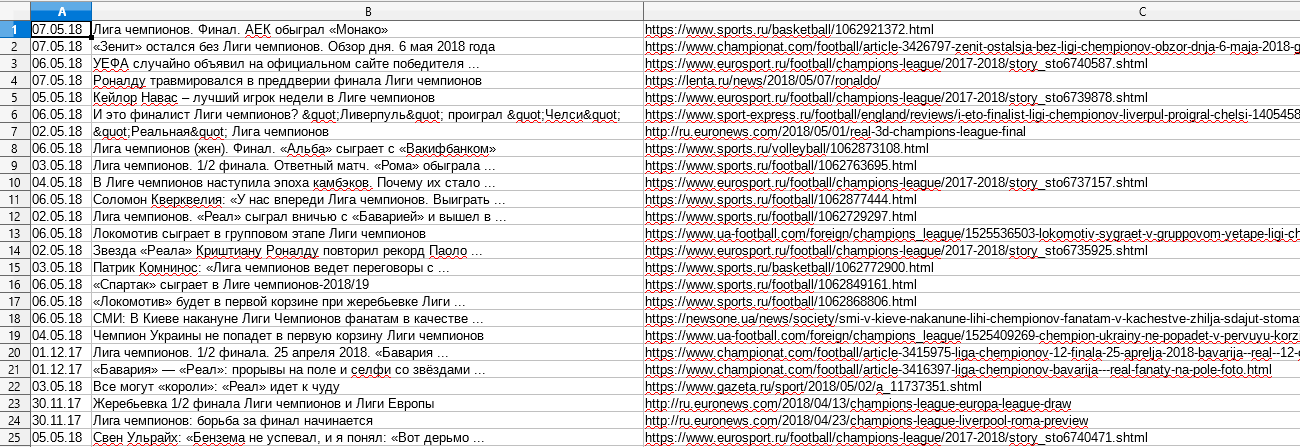
В поисковой выдаче Google возле новостей публикуется дата. Как правило, это могут быть метки "10 ч. назад" или "26 мая 2018 г.". Иногда может возникнуть задача спарсить все даты и привести их к единому виду. Как именно это сделать, можно узнать по ссылке выше.
24-й сборник рецептов. В нем мы научимся мониторить окончание срока регистрации доменов с уведомлением в Телеграм, сделаем альтернативный чекер сайтов в базе РКН, а также на простом примере парсера курсов валют изучим работу с базами данных. Поехали!
Мониторинг сроков регистрации доменов - это довольно распространенная задача. A-Parser позволяет легко автоматизировать этот процесс. Более того, можно настроить получение прямо в Телеграм уведомлений о доменах, срок регистрации которых скоро закончится. Готовое решение для автоматической проверки с уведомлением - по ссылке выше.
В А-Парсере есть стандартный парсер [parser]Check::RosKomNadzor[/parser], который позволяет проверять наличие сайтов в базе РКН. Данные получаются напрямую из официального сервиса, для работы обязательно нужно подключать антигейт. Кроме того, официальный сервис РКН часто подвергается атакам, в связи с чем может быть недоступен. Но существуют альтернативные источники данных, доступность которых значительно выше и к тому же не требующие проверки в виде каптчи. Парсинг одного из таких источников и реализован в пресете по ссылке выше.
Как известно, в A-Parser есть возможность чтения/записи данных в БД SQLite. В этом рецепте показано использование этого функционала на примере парсинга курсов валют. Готовый парсер доступен по ссылке выше.
В
Rank::CMS обновлена база определяемых движков, теперь поддерживается одновременно старый и новый формат apps.json (при обновлении рекомендуется также обновить apps.json)
Очень рад что являюсь пользователем программного комлекса aparser.
Этот софт развивается и становиться лучше, постоянные оптимизации и улучшения, частые обновления все это очень радует, учитываются хотелки и замечания не оставляют без внимания.
Еще нравится что форум тех.поддержки дружелюбный там всегда подскажут когда неполучается.
Рекомендую aparser всем кто ценит свое время!
В 4-м сборнике статей будет рассмотрено добавление товаров в OpenCart, а также описано создание универсального парсера JSON. В каждой статье приложены готовые JS парсеры, используя которые, можно на реальных примерах изучить описанные методы и поэксперементировать с ними. Поехали!
Данная статья начинает цикл об одной из наиболее часто запрашиваемых возможностей - заливке товаров в интернет-магазин. A-Parser - это универсальный инструмент, который кроме прочего может решать и такие задачи. Для тестов выбран движок OpenCart, в 1-й статье будет рассмотрена авторизация, получение списка товаров и добавление товара. Подробности, а также пример парсера - по ссылке выше.
JSON - это довольно популярный способ предоставления данных, который, например, часто используется при работе с API различных сервисов. В А-Парсере есть встроенные инструменты для работы с ним, но не всегда их применение может быть простым, иногда требуется дополнительно писать сложные шаблоны, используя шаблонизатор. Поэтому в статье по ссылке выше будет рассказано, как написать простой универсальный парсер JSON.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.






















 ) - отписывайтесь
) - отписывайтесь